Nghiên cứu kỹ thuật học sâu cho bài toán phân lớp dữ liệu tiếng Việt
Từ khóa:
Tóm tắt
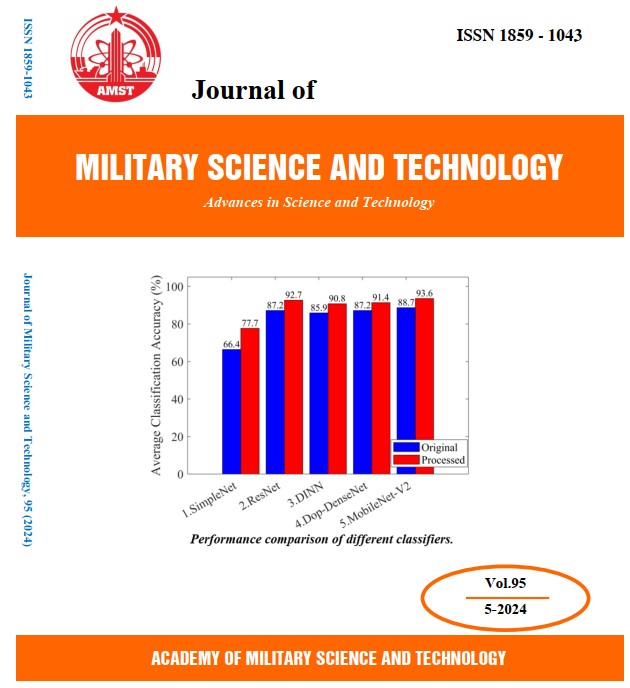
Phân loại văn bản nhằm mục đích tự động gán các đoạn văn bản hoặc tài liệu nhất định thuộc vào các danh mục hoặc chủ đề được xác định trước. Mặc dù có rất nhiều kỹ thuật được sử dụng để phân loại văn bản tiếng Anh nhưng vẫn còn thiếu các nghiên cứu về phân loại văn bản tiếng Việt. Bài viết này giới thiệu một cách tiếp cận mới sử dụng Bộ nhớ ngắn hạn dài (LSTM) và Mạng tích chập (CNN) với cấu trúc mạng nơ-ron sâu để phân loại văn bản tiếng Việt. Phát hiện của chúng tôi chứng minh sự cải thiện đáng kể về độ chính xác trong phân loại khi áp dụng các kỹ thuật học sâu cho hai tập dữ liệu tin tức tiếng Việt. Nghiên cứu này góp phần thúc đẩy sự cải tiến của phân loại văn bản tiếng Việt bằng cách giới thiệu và chứng minh tính hiệu quả của LSTM và CNN với cấu trúc mạng sâu. Kết quả mang lại những hiểu biết sâu sắc có giá trị cho các nhà nghiên cứu và thực hành nghiên cứu về phân loại văn bản trong tiếng Việt.